Digital Trace Data
Introduction to digital trace data`:` Quality, ethics, and analysis. Utrecht University
Updated at: 20 August 2025 (Javier Garcia-Bernardo, Laura Boeschoten, and Thijs Carrière)
Group project guidelines
The group project is a central part of the course. The project is designed to give you hands-on experience with digital trace data, and to apply the knowledge you have gained in the course to a real-world problem. In the practical you will work in groups to collect text data, label it using Natural Language Processing models, discuss the errors and biases that you encounter in the data, and interpret the results in light of the errors.
The slides used in the first lab are available here.
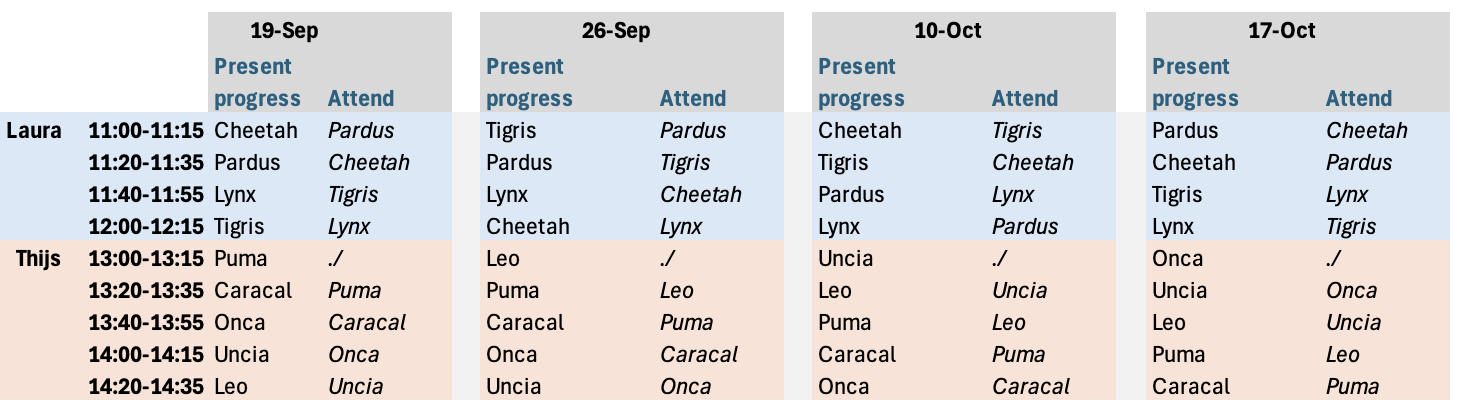
Timeslots for the feedback moments (see dates and location on MyTimetable)
- Location: DALTON 500 - 5.09 or BOL - 1.152 (please double check on MyTimetable)
- Come prepared: As a group, prepare and bring some slides with your progress so far and your proposed next steps. Important: each slide should state the name of the group members who contributed to that part of the project. You can add an extra slide at the end with other tasks done by the group members that are not shown in the other slides. Send your slides to your feedback moment’s teacher in advance—either to Thijs or Laura ({t.c.carriere, l.boeschoten}@uu.nl).
Practical information
- The project consists of two assignments, each worth 30% of the final grade.
- The groups will be formed in the first practical. If you miss the first practical, you will not be able to participate in the group project and will fail the course.
- The progress will be tracked in four feedback sessions, a 15 minute meeting with the lecturers to discuss the progress of the project. Attendance to the feedback sessions is mandatory.
- Upload the the written report and the presentation through the link on the home page. Please name your file groupX_report.pdf, groupX_presentation.pdf.
Assignment 1: Errors in data collection (30% of the grade)
In the first assignment you will develop a research question, collect text data using one of the methods explained in the lectures/labs (data donation, plug-ins, scraping, APIs), and identify and discuss the errors that you anticipate and encounter when collecting data to answer it.
The outcome is a short report (<1,000 words excluding references and potential figures) that you will submit in week 5 (see weekly schedule). You will receive feedback from the lecturers during the feedback sessions (weeks 3 and 4).
Please find the template and the rubric of assignment 1 here.
Steps:
- During the final 20 minutes of the first lab meeting, discuss as a group how you envision working together. Discuss each person’s responsibilities and make agreements on how to collaborate. You can use the group contract for this, which can be found here.
- Decide on a specific research question and a target dataset. Since you will use the data in the second assignment, make sure that the data is suitable for the analysis you have in mind. In the second assignment, you will label the data using text classification models using a machine learning model. These models classify text, for example detecting the presence of hate speech, political leaning, personality traits or different emotions. We recommend you to use one of the proposed themes: political polarization, hate speech, personality traits, or mental health. Some of the research questions from previous years are:
- How does the Spotify listening behavior of Utrecht University students towards music change over the course of the academic year?
- Do supporters of Donald Trump spread more hate speech on social media in the month after the July 13th assassination attempt compared to the month before the attempt?
- What attitudes towards the actions of radical climate activists are visible on Reddit?
- Take a quick look at the PRIDE Questionnaire for approval Single Study, which helps conduct the project in an ethically responsible manner and in accordance with legislation. You will only need to complete it for the second assignment, but it is a good idea to start thinking about the ethical implications of your project from the beginning.
- Start collecting the data using the methods explained in the lectures/labs: either data donation/plug-ins (lab 2), or scraping/APIs (lab 3). In the unlikely case that you are using participants, you will need to create an informed consent form. For that, talk with your project supervisor (either Thijs or Laura).
- Attend Feedback session I (week 3) to discuss your progress. Prepare a few (<5) slides with your progress which indicates on what topics each group member worked (each slide should contain the contributors). Send your prepared slides to your project supervisor (either Thijs or Laura) before the meeting. Bring already some of the collected data.
- Finish collecting the data and discuss the errors (representation and measurement) that you anticipate when answering the research question with the proposed data.
- Attend Feedback session II (week 4) to discuss your progress. Prepare a few slides with your progress and again send these to the teacher you have the feedback session with prior to this meeting.
- Finish assessing the errors in the data, ideally by comparing the data with other sources of information (e.g. representative surveys).
- Submit a short report (<1,000 words excluding references and potential figures) in week 5 (see weekly schedule). The link for handing in the report can be found on the course’s homepage.
Grading:
- Process: 30% (work, communication and preparation for feedback sessions). This is an individual grade.
- Report: 70% This is a group grade.
Assignment 2: Errors in data labeling and moving past errors
In the second assignment you will further analyze the data collected in the first assignment to answer the RQ. For this you will use a Natural Language Processing model of your choice to label the data, which you will learn on week 5. These type of models can predict things from text. For example, they can predict if the text contains hate speech, polarized content, negative language, or specific personality traits. You will discuss the biases that you encounter in the labeling process, and how you will move past these errors in data collection and data labeling.
The outcome is a final presentation (12 minutes + 5 minutes of Q&A) that you will present in week 8 (see weekly schedule). Please submit the final presentation using the upload link before 23:59 in the day of the deadline (see weekly schedule). Name your slides groupX_presentation.pdf/pptx.
Please find the template and the rubric of assignment 2 here.
You will receive feedback from the lecturers during the feedback sessions (weeks 6 and 7).
Steps:
- Run a text classification model of your choice from Hugging Face on the data collected in the first assignment. These models classify text, for example detecting the presence of hate speech, political leaning, personality traits or different emotions. The model should be appropriate to answer your research question. If you would like to use LLMs (e.g., GPT-5) for labeling, you can look at the materials here. Please be aware that using LLMs costs money (for a typical project in the course, usually less than one euro).
- Reflect on the biases you expect during the labeling process, and the origin of those biases.
- Attend Feedback session III (week 6) to discuss your progress. Prepare a few of slides with your progress and send these to your teacher prior to the meeting. Make sure the slides indicate who worked on what topics.
- Reflect on how you would expand the study to tackle these issues. What type of data would you need to collect?
- Complete the PRIDE Questionnaire for approval Single Study, which helps conduct the project in an ethically responsible manner and in accordance with legislation.
- Reflect on the ethical principles discussed through the course. Is your project aligned with them?
- Draft the final presentation.
- Attend Feedback session IV (week 7) to discuss your progress. Prepare a few slides with your progress. Bring the completed PRIDE questionnaire.
- Submit the slides and the PRIDE form before the deadline (see weekly schedule) through the link on the home page. Please name your file groupX_PRIDE.pdf, groupX_presentation.pdf.
- Present the group project in week 8 (see weekly schedule). Groups Cheetah, Pardus, Lynx and Tigris are present from 11:00 - 13:00. Groups Onca, Uncia, Leo, Puma and Caracal are present from 13:00 - 15:00. We expect all groups to actively engage with questions and discussion.
- During the presentations, we require all other groups to active participate in the discussion and ask questions.
Grading:
- Process: 30% (work, communication and preparation for feedback sessions). This is an individual grade.
- Presentation: 70%. This is a group grade.